Development of
Overview
DNA-encoded libraries (DEL) have become a powerful approach for identifying potential drug candidates in early-stage drug discovery. However, analyzing DEL sequencing results requires sophisticated computational workflows capable of processing large volumes of next-generation sequencing (NGS) data while accurately identifying meaningful compound hits.
Excelra collaborated with a European pharmaceutical company to develop a hit-calling algorithm on DEL selection data that could reliably identify candidate molecules from large sequencing datasets. By combining advanced Bioinformatics Solutions, robust Scientific Data Management, and scalable computational pipeline platforms, Excelra created an automated workflow capable of processing high-throughput DEL datasets and improving hit identification for drug discovery.

Our client
The client is a European pharmaceutical company dedicated to discovering and developing small-molecule therapeutics with novel mechanisms of action. Their research team required advanced computational tools to analyze large DNA-encoded library datasets and identify promising compounds for further testing.

Client’s challenge
DNA-encoded library experiments generate massive volumes of sequencing data that must be carefully analyzed to identify meaningful compound hits.
The client faced several challenges:
- Processing large volumes of next-generation sequencing (NGS) data
- Limited compound coverage within DEL datasets
- High noise levels in sequencing data affecting hit detection
- Difficulty distinguishing true hits from false positives
- Need for a scalable algorithm integrated with high-throughput drug discovery workflows
To address these challenges, the client required a statistical approach capable of improving hit identification accuracy while handling noisy datasets.

Client’s goals
The project aimed to:
- Develop a hit-calling algorithm for DEL selection data
- Improve detection of true compound hits
- Reduce false positives in sequencing analysis
- Integrate DEL analysis into automated computational pipelines
- Enable scalable NGS data processing for drug discovery workflows
Our approach
DEL dataset analysis
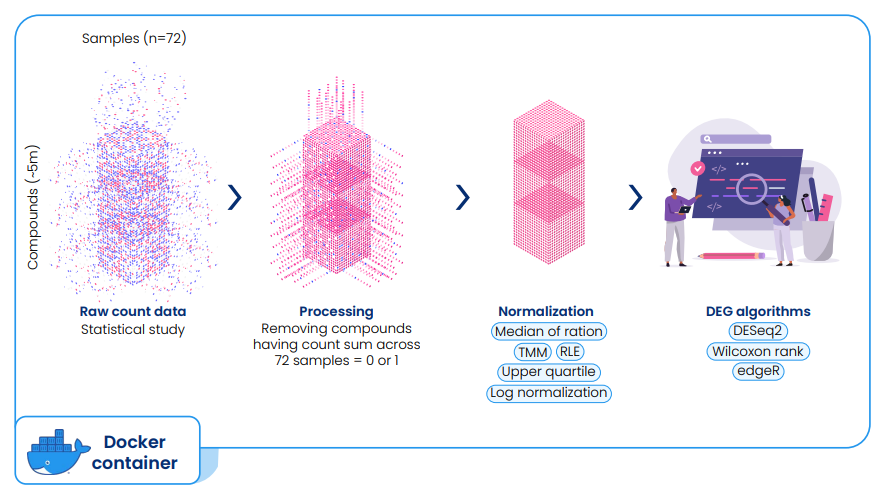
Excelra began the project with a comprehensive bioinformatics analysis of the DEL dataset. The dataset consisted of 72 samples containing raw count data for approximately 5 million compounds in the client’s library.
Because low raw count values increased the risk of false positives or missed hits, data normalization was critical for accurate hit identification.
Data standardization and normalization
Excelra implemented data standardization techniques and statistical normalization workflows to ensure reliable signal detection while preserving key trends in the dataset.
These approaches align with modern data-driven drug discovery frameworks discussed in big data and artificial intelligence in drug discovery.
Algorithm selection
Multiple differential gene expression (DEG) algorithms were evaluated to determine the most suitable statistical approach for the DEL dataset.
After comparative analysis, DESeq2m was selected as the optimal algorithm due to its ability to:
- Handle low-count sequencing data
- Improve statistical reliability
- Detect meaningful enrichment signals
Computational pipeline development
The selected algorithm was integrated into a containerized computational workflow using Nextflow, enabling scalable and reproducible NGS data processing.
The pipeline was deployed on Excelra’s online pipeline platform, ensuring:
- Automated processing of DEL sequencing datasets
- Reproducible analytical workflows
- Scalable computational infrastructure
Our solution
Excelra successfully developed a robust computational pipeline capable of accurately identifying compound hits within large DEL datasets.
Key outcomes
- Development of a hit-calling algorithm optimized for DEL selection data
- Improved detection of true compound hits
- Reduction of false positives caused by noisy sequencing data
- Integration of the algorithm into a scalable Nextflow-based pipeline
- Automated processing of large NGS datasets for high-throughput screening
Key benefits
- Improved hit identification
The algorithm significantly enhanced detection of promising compounds in DEL screening data. - Scalable NGS data processing
The containerized workflow enabled automated and scalable analysis of sequencing datasets. - Reliable drug discovery insights
Robust statistical methods improved the accuracy of compound selection for downstream validation.
Conclusion
Excelra’s development of a hit-calling algorithm for DEL selection data enabled accurate identification of candidate molecules from complex sequencing datasets. By combining advanced bioinformatics analysis, statistical modeling, and automated computational pipelines, Excelra delivered a scalable solution that improves hit discovery in DNA-encoded library screening.
This project highlights Excelra’s capabilities in bioinformatics, NGS data analysis, and digital transformation in drug discovery, helping pharmaceutical organizations accelerate compound screening and therapeutic discovery.
For related research insights, explore Excelra’s expertise in DNA-encoded library analysis and additional case studies.
