
Text mining - Unlocking intelligent insights from immense data
The conversion of unstructured data into high-quality actionable insights based on information retrieval, data mining, machine learning, statistics, and computational linguistics is commonly referred to as text mining. Accessibility to such organized information enables data-driven decisions, extraction of previously unknown knowledge, and building of new data patterns. News articles, plain text, technical papers, books, digital libraries, emails, blogs, and internet pages are few sources of such data1. From academia and healthcare to businesses and social media platforms, text mining processes have found utility in web mining, risk management, cybercrime prevention, business intelligence, content enrichment, customer care service, and knowledge management for generating value and ROI from unstructured data2. In this regard, the availability of large volumes of unstructured biological and biomedical data necessitates the need to integrate manual curation and computational methods for literature mining, to drive meaningful data-centric outcomes in academia, pharma, and healthcare.
The 5-Steps of text mining
Text mining in any domain broadly constitutes the following 5 steps:
- Data acquisition
- Text pre-processing and transformation (cleansing)
- Text selection, extraction and organization
- Text evaluation and validation
- Application
Text mining for biology & biomedical data - Need for integrating automation with manual expertise
A biology or biomedical data text mining tool requires the combination of computational and manual curation approaches for optimal performance and development of comprehensive databases in a timely manner. Often data-centric organizations that utilize computational text mining methods to develop domain-specific services or products are dependent on outsourced help to manually curate/evaluate data. It is therefore imperative to have data curation, automation and evaluation under one roof to support end-to-end functioning of an in-house text mining tool.
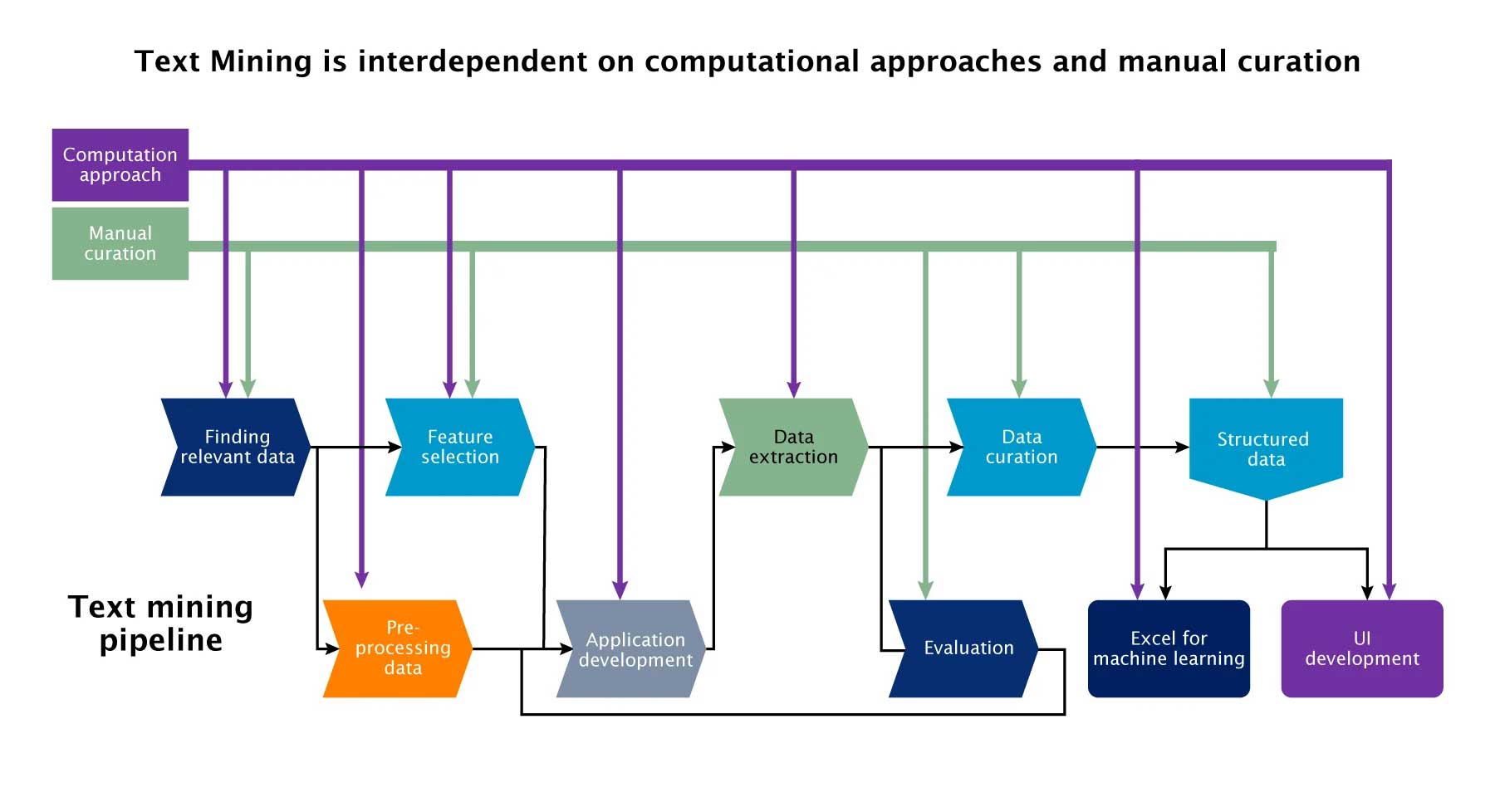
Fig.1: Multiple steps associated with text mining processes and steps that require both computational and manual curation interventions.
Biology curation services & text mining at Excelra
Biomedical text mining requires expert curation of data and projection of meaningful data insights. Excelra is a hub of domain experts in the field of biomedical data curation and provides a repertoire of computational biology services, bioinformatics services and biology curation services. Our experts use computational biology tools like NLP, coupled with manual data analysis interventions to process unique requirements of clients. The outcome is clean, organized and structured data with a range of applications:
- Extraction of previously unknown knowledge
- Deriving new data patterns with analysis-ready data for training AI/ML pipelines
- Enabling informed data-driven decisions to accelerate Biopharma R&D
Excelra's text mining approaches
Our text mining approaches are tailored to the needs of customers and is dependent on the type of input data.
- A traditional ‘keyword-based approach’ may only discover relationships at a shallow level, while ‘tagging-based approaches’ may rely on tags obtained manually or by automated algorithms.
- A more advanced information-extraction approach requires ‘semantic analysis of text’ by NLP and machine learning methods.
- At Excelra, we have provided all three kinds of services with varying input data from canonical search engines, PubMed like scientific literature search engine, news reports, client specific articles and scientific databases. Our years of experience coupled with domain expertise in the field position us a formidable player to meet client specific requirements in critical projects in data curation services.
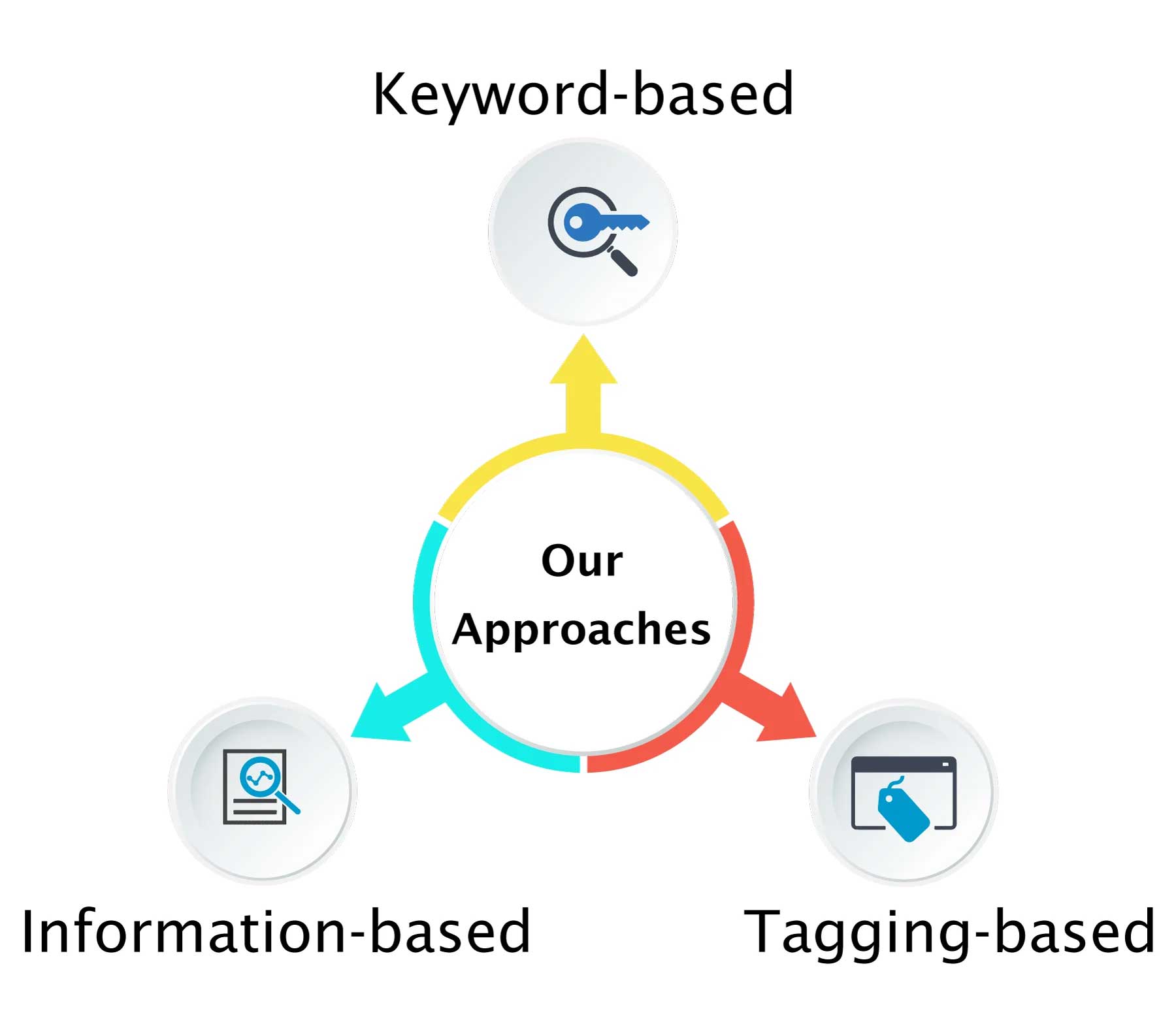
Fig.2: Schematic representation of Excelra’s three approaches for text mining of biomedical data
Case Study
Excelra has been providing biomedical data curation and text mining services to multiple clients, each customized to meet specific needs. To underscore the utility of our in-house text mining tool, a client case study is presented here.
Objective
The project aimed to develop datasets with experimentally approved protein degrading enzyme pairs. The scope was to identify relevant degrading enzyme-substrate pair databases, extract data with pre-defined features using the text mining pipeline, and lastly deliver structured curated data. These outcomes were further implemented in machine learning (ML) enabled data analysis and in user interface (UI) based data visualizations.
Methodology for literature mining
The entire process was 3 phased.
- In phase 1, datasets with protein degrading enzyme-substrate relations from PubMed and PMC were found as suitable data sources with experimentally proven protein degrading enzyme-substrate associations. A sentence construction exercise was conducted to identify salient features that represent the data to be identified.
- In phase 2, a lexicon of enzymes and degradation keywords were developed. A text mining tool based on elastic search and integrated with the lexicon and identified features was established. The tool was applied on the processed data. The manual evaluation of the text mining tool extracted articles had confirmed accuracy >90%. In total, the tool could identify 2000 relevant PubMed articles and 9500 PMC articles.
- Finally, the full text articles with experimentally proven protein degrading enzyme-substrate links were manually curated based on 25 pre-defined variables in phase 3. A spreadsheet with curated data was provided for use in machine learning, and a UI was developed for data visualization.
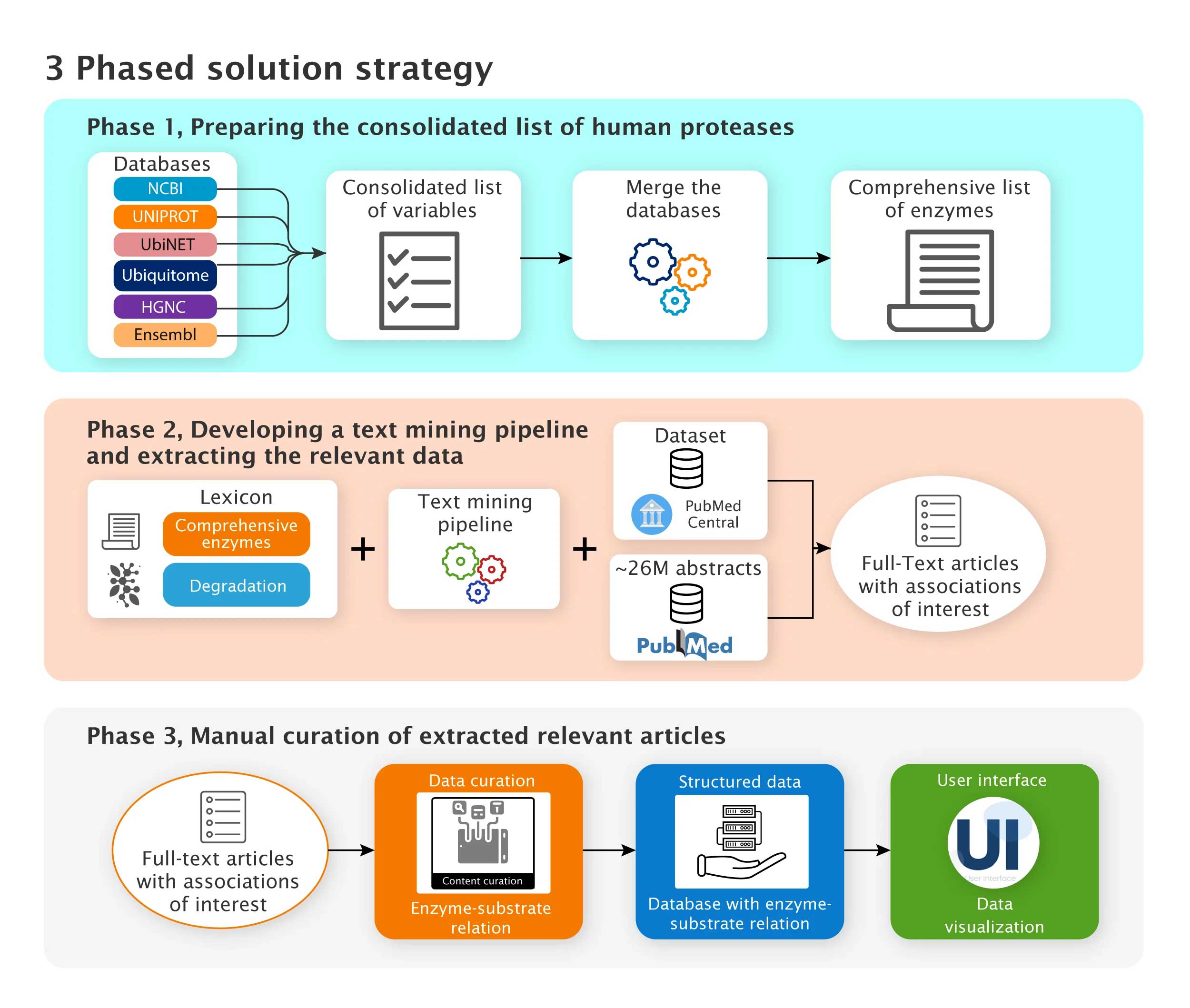
Fig. 3: The 3-phased solution strategy for developing a dataset with experimentally proven protein degrading enzyme-substrate relations using text mining and manual curation
The Excelra Edge
The key differentiators that set Excelra apart from other domain experts can be summarized in the following points:
- Excelra has been providing expert support to 15 of the top 20 pharma companies, with 90+ clients spread across the globe
- It holds 18+ years of experience in data sciences with 60+ PhDs among a 600+ talent pool
- The organization is equipped with data, deep domain expertise and data science capabilities
- Excelra has a scalable multilingual techno-human curation engine
- A customized ontology-based approach with expert curated relevant scientific terms specific for each text mining project is another differentiator
- Domain experts who are well-experienced in handling versatile text mining projects
- Finally, presence of a multidisciplinary blend of Math, Computation, and Life Sciences under one roof with proprietary text mining algorithms enables Excelra to develop text mining tools with optimal performance in quick turnaround time
Fig. 4: The Excelra Edge with key differentiators
Conclusion: Advantages & the imperative need for text mining solutions to derive actionable insights from biomedical literature
Text mining in biomedical/scientific literature could provide significant benefits in finding new data patterns and in knowledge extraction management. Today, large volumes of biological and biomedical data are being churned out at an exponential rate due to usage of multi-experimental methods such as Omics technologies. These investigational data are further published in peer-reviewed journals and get indexed in public literature repositories such as PubMed or Medline. Researchers query and use this primary literature data to generate new hypotheses or validate their own results, while scientific curators manually curate and survey such data to populate databases with varied functionalities. Manual efforts are however labor-intensive, consume enormous time, and require extensive searches to obtain relevant information. Extracting and processing research outcomes from literature repositories using AI-enabled technologies like NLP, ML, and languages such as Python or R could possibly offer new and valuable biological insights. Also, applying text mining methods on clinical data could benefit in understanding disease pathogenesis, development of new diagnostics and drugs, efficient patient data management systems, and implementation of precision medicine amongst a repertoire of probable clinical solutions 3. Text mining of biomedical data thus holds immense promise and could pave the way to new innovations across several domains such as academia, pharma, and healthcare.
