
Text mining - Unlocking intelligent insights from immense data
The conversion of unstructured data into high-quality actionable insights based on information retrieval, data mining, machine learning, statistics, and computational linguistics is commonly referred to as text mining. Accessibility to such organized information enables data-driven decisions, extraction of previously unknown knowledge, and building of new data patterns. News articles, plain text, technical papers, books, digital libraries, emails, blogs, and internet pages are few sources of such data1. From academia and healthcare to businesses and social media platforms, text mining processes have found utility in web mining, risk management, cybercrime prevention, business intelligence, content enrichment, customer care service, and knowledge management for generating value and ROI from unstructured data2. In this regard, the availability of large volumes of unstructured biological and biomedical data necessitates the need to integrate manual curation and computational methods for literature mining, to drive meaningful data-centric outcomes in academia, pharma, and healthcare.
The 5-Steps of text mining
Text mining in any domain broadly constitutes the following 5 steps:
- Data acquisition
- Text pre-processing and transformation (cleansing)
- Text selection, extraction and organization
- Text evaluation and validation
- Application
Text mining for biology & biomedical data - Need for integrating automation with manual expertise
A biology or biomedical data text mining tool requires the combination of computational and manual curation approaches for optimal performance and development of comprehensive databases in a timely manner. Often data-centric organizations that utilize computational text mining methods to develop domain-specific services or products are dependent on outsourced help to manually curate/evaluate data. It is therefore imperative to have data curation, automation and evaluation under one roof to support end-to-end functioning of an in-house text mining tool.
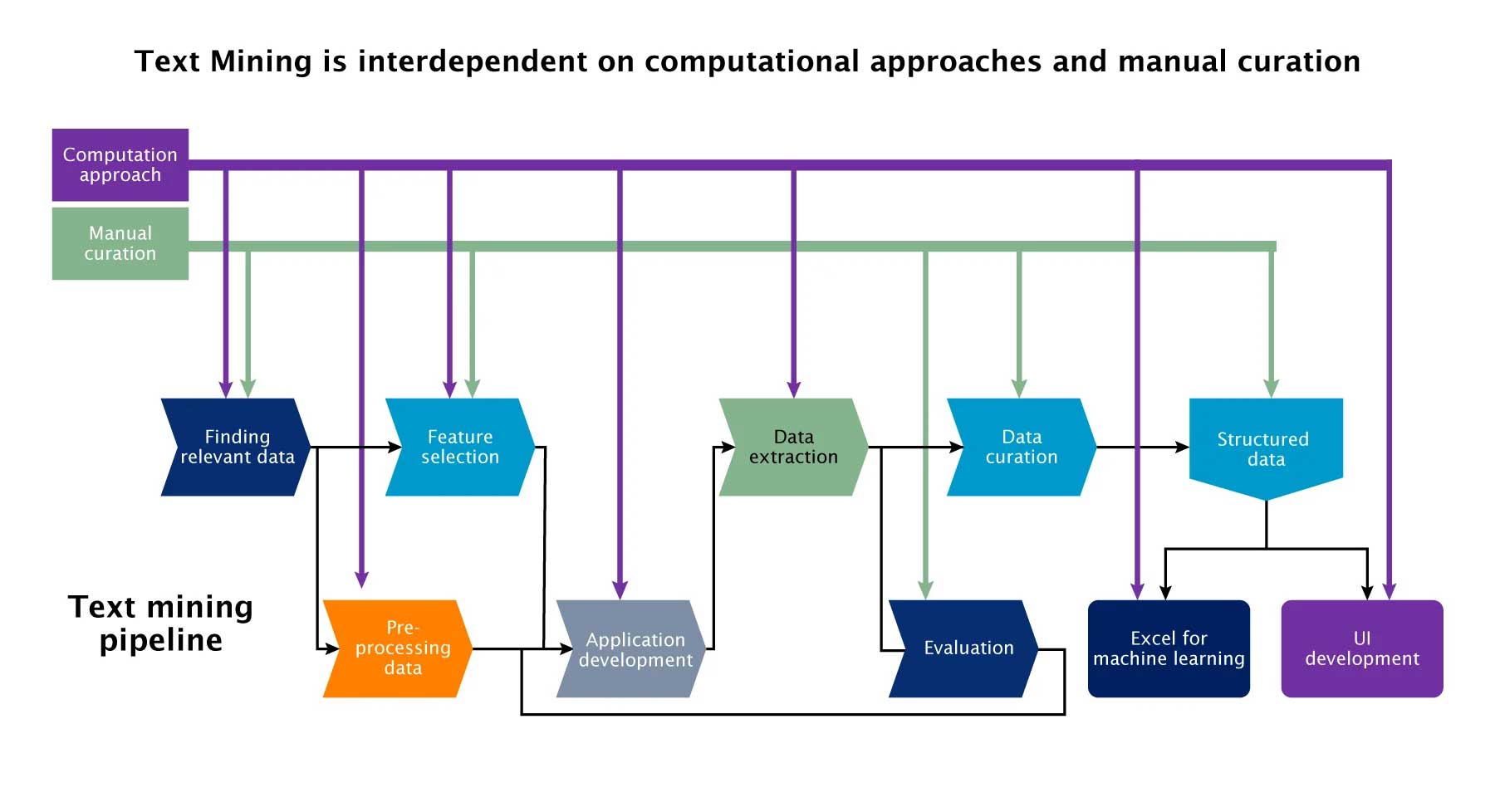
Fig.1: Multiple steps associated with text mining processes and steps that require both computational and manual curation interventions.
Biology curation services & text mining at Excelra
Biomedical text mining requires expert curation of data and projection of meaningful data insights. Excelra is a hub of domain experts in the field of biomedical data curation and provides a repertoire of computational biology services, bioinformatics services and biology curation services. Our experts use computational biology tools like NLP, coupled with manual data analysis interventions to process unique requirements of clients. The outcome is clean, organized and structured data with a range of applications:
- Extraction of previously unknown knowledge
- Deriving new data patterns with analysis-ready data for training AI/ML pipelines
- Enabling informed data-driven decisions to accelerate Biopharma R&D
Excelra’s text mining approaches
Our text mining approaches are tailored to the needs of customers and are dependent on the type of input data. Excelra combines advanced automation with expert-led data curation services to enable scalable and reliable biomedical knowledge extraction.
A traditional ‘keyword-based approach’ may only discover relationships at a shallow level, while ‘tagging-based approaches’ may rely on tags obtained manually or by automated algorithms. A more advanced information-extraction approach requires semantic analysis of text using NLP and machine learning methods, as discussed in our detailed blog on integrated text mining and data curation approaches.
At Excelra, we have provided all three kinds of services with varying input data from canonical search engines, PubMed-like scientific literature search engines, news reports, client-specific articles, and scientific databases. Our years of experience, coupled with strong bioinformatics expertise, position us as a formidable partner for complex biomedical text mining and analytics initiatives.
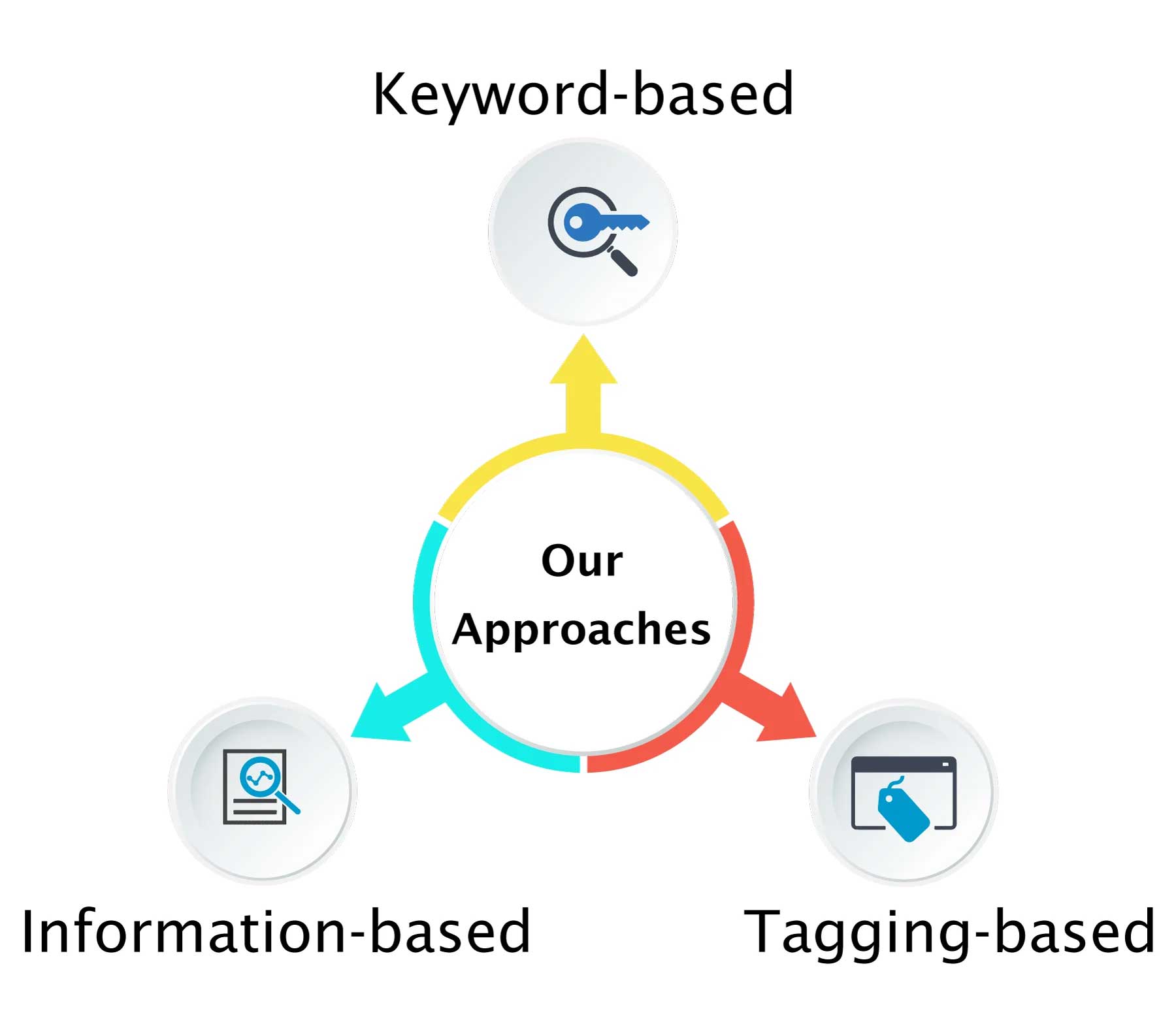
Fig.2: Schematic representation of Excelra’s three approaches for text mining of biomedical data
Case Study
Excelra has been providing biomedical data curation and text mining services to multiple clients, each customized to meet specific needs. To underscore the utility of our in-house text mining tool, a representative case study is presented below.
Objective
The project aimed to develop datasets with experimentally approved protein degrading enzyme pairs. The scope included identifying relevant enzyme–substrate databases, extracting data using a robust text mining pipeline, and delivering structured, curated datasets. These outputs were further used in machine learning–driven data analysis and UI-based visualizations.
Methodology for literature mining
The entire process was executed in three phases.
Phase 1: Datasets containing protein degrading enzyme–substrate relationships were sourced from PubMed and PMC, focusing on experimentally validated associations. A sentence construction exercise was conducted to define salient data features.
Phase 2: A lexicon of enzymes and degradation-related keywords was developed. A text mining tool built on Elasticsearch and integrated with domain lexicons was applied to the processed literature. Manual evaluation confirmed an accuracy of over 90%, identifying approximately 2,000 PubMed articles and 9,500 PMC articles.
Phase 3: Full-text articles were manually curated using 25 predefined variables. The resulting structured datasets were delivered as analysis-ready spreadsheets to support downstream AI/ML workflows and visualization platforms, similar to Excelra’s data visualization services.
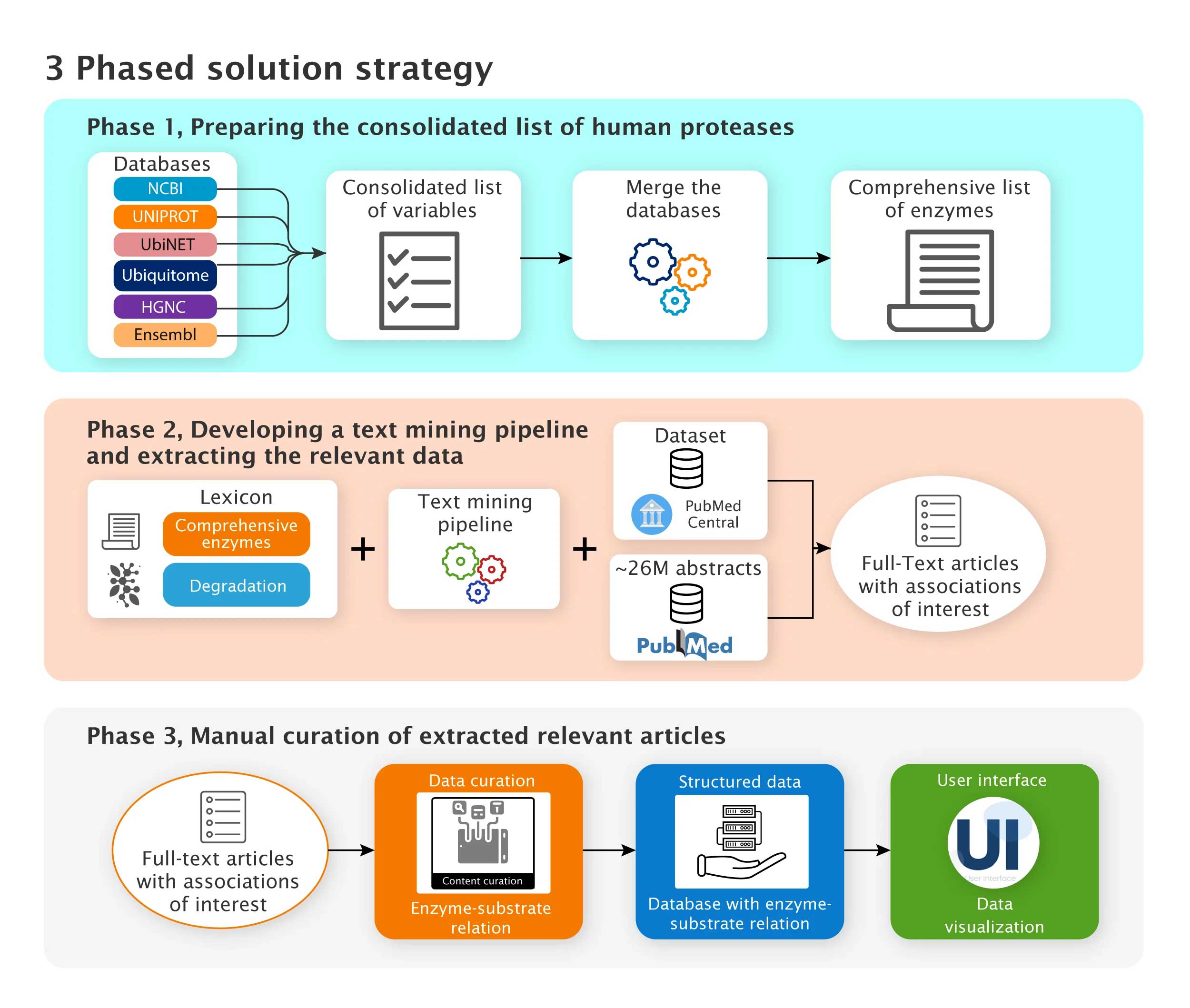
Fig. 3: The 3-phased solution strategy for developing a dataset with experimentally proven protein degrading enzyme-substrate relations using text mining and manual curation
The Excelra Edge
The key differentiators that set Excelra apart from other domain experts include:
- Trusted partner to 15 of the top 20 pharma companies, with 90+ global clients
- 18+ years of experience in data sciences with 60+ PhDs across a 600+ member talent pool
- Strong capabilities across scientific informatics, data science, and deep life sciences domain expertise
- A scalable, multilingual techno-human curation engine
- Customized ontology-driven approaches aligned with FAIR data principles
- Proprietary text mining algorithms enabling rapid turnaround with high accuracy
Fig. 4: The Excelra Edge with key differentiators
Conclusion: Advantages & the imperative need for text mining solutions
Text mining of biomedical literature enables efficient knowledge extraction, discovery of new data patterns, and accelerated scientific insights. With exponential growth in omics-driven research and publications indexed in repositories such as PubMed and Medline, manual curation alone is no longer scalable. AI-enabled approaches using NLP, ML, and data science techniques—similar to those used in big data–driven drug discovery—offer significant advantages.
Applying text mining to clinical and biomedical data supports improved understanding of disease pathogenesis, biomarker discovery, diagnostics, and precision medicine. As demonstrated across multiple AI/ML-driven case studies, Excelra’s integrated text mining and curation frameworks continue to drive innovation across academia, pharma, and healthcare.
