Overview
This case study focuses on predictive biomarkers for patient enrichment identified using machine learning and gene expression analysis to improve drug-response prediction during clinical development. By applying bioinformatics solutions, robust scientific data management, and validated analytics frameworks, Excelra enabled data-driven patient stratification for upcoming clinical trials.
The approach aligns with industry-accepted biomarker strategies described by organizations such as the National Institutes of Health (NIH) and published clinical research standards.

Our client
The client is a pharmaceutical company in the clinical development phase of a pipeline molecule, seeking to strengthen patient enrichment strategies. Their focus was on identifying drug response biomarkers from proprietary gene expression datasets to improve clinical trial outcomes and accelerate development timelines.

Client’s challenge
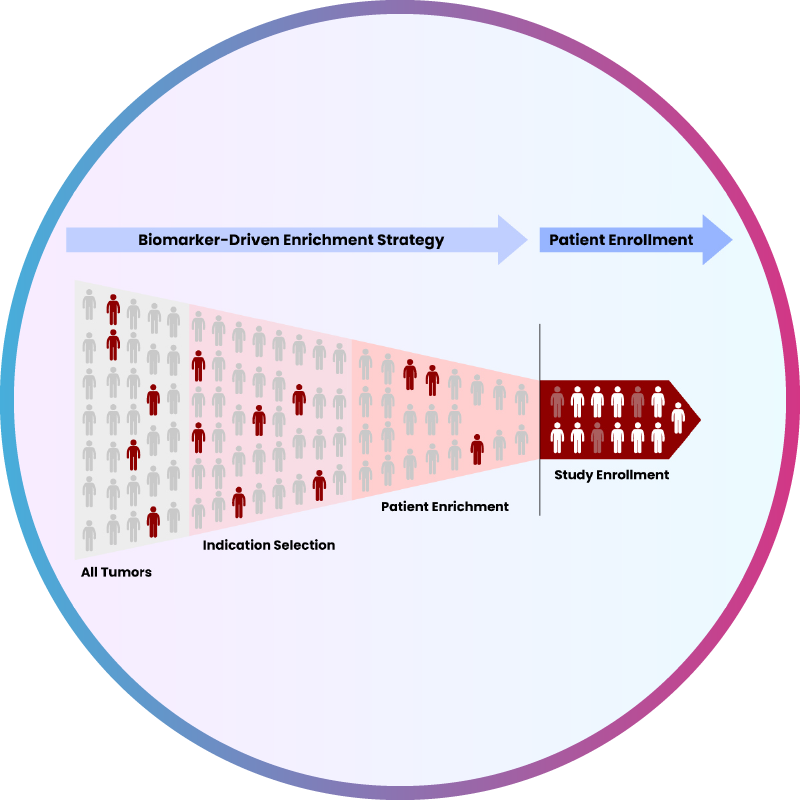
Traditional biomarker analysis approaches made it difficult to accurately predict drug response across heterogeneous patient populations. The client needed a scalable and reproducible method to analyze large-scale gene expression data, identify predictive biomarkers, and retrospectively classify patients into responders and non-responders.
Without an advanced analytics framework, patient selection relied heavily on manual interpretation, increasing variability and limiting the effectiveness of FAIR data principles in life sciences.

Client’s goals
- Identify predictive biomarkers associated with drug response
- Enable robust patient stratification for clinical trials
- Improve enrichment strategies using AI-driven analytics
- Support clinical development with scalable scientific informatics services
Our approach
Machine Learning–Driven biomarker identification
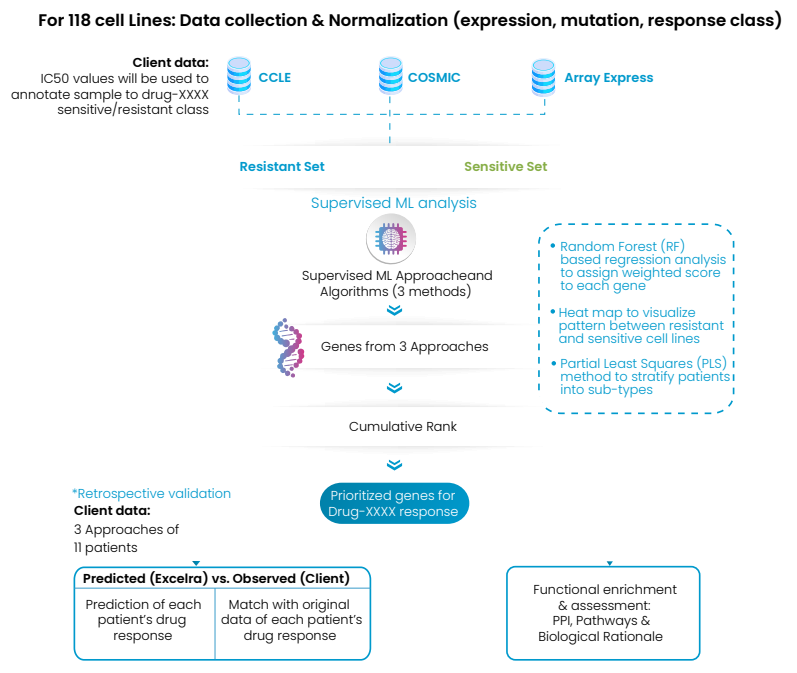
Excelra developed multiple machine learning models to prioritize biomarkers linked to drug response. These models analyzed gene expression profiles from treated cell lines, enabling unbiased identification of high-confidence predictive biomarkers.
Pathway enrichment and biological interpretation
To understand the biological relevance of the identified biomarkers, pathway enrichment analysis was performed. This helped link biomarkers to disease mechanisms and drug mode of action, aligning insights with predictive analytics best practices.
Patient stratification and validation
Using the shortlisted biomarkers, patients were stratified into responders and non-responders. This approach correctly predicted drug response in 8 out of 11 patients, demonstrating the effectiveness of data-driven drug discovery and enrichment strategies.
Our Solution
Excelra delivered a predictive biomarker discovery framework combining machine learning, bioinformatics visualization, and advanced data visualization. The solution enabled:
- Accurate patient enrichment for clinical trials
- Improved confidence in drug-response prediction
- Scalable reuse across future development programs
The structured datasets and analytics outputs were aligned with FAIR data principles in pharma, ensuring reproducibility and long-term usability.
By integrating predictive biomarkers, patient enrichment strategies, and machine learning-based bioinformatics, Excelra enabled the client to achieve reliable drug-response prediction and strengthen clinical decision-making. This case study demonstrates how digital transformation in drug discovery can accelerate clinical development and improve trial success.
Looking to implement predictive biomarkers and patient enrichment strategies in your clinical programs? Connect with Excelra’s experts to explore tailored bioinformatics and scientific informatics solutions.
Conclusion
Our approach directly addressed the GSNAP trade-off: GSNAP’s high sensitivity mapping was retained, while drastically improving runtime and reducing wasted computational resources caused by failures due to low quality. This allowed this RNA workflow that demands full alignments to scale—keeping the technical advantages of seed-and-extend and simultaneously preserving quality features—without the prohibitive cost and wall time typically associated.
Over the course of just ten weeks of this pilot study, we successfully delivered a robust automated, cloud-compatible, Nextflow pipeline from the legacy Perl codes.
The success of this pilot study led the client to both continue and expand the scope of this project, wherein the GSNAP RNA-seq pipeline was expanded to contain all the original over 100 steps of quality control, validation, alignment, counts generation, and reporting. Visualization tools were also generated. This work is on-going.
