
Contributors: Nishanth Kandepedu
Date: Oct’24
Introduction
Most drug discovery programs prioritize developing orally bioactive small-molecule medicines as they are the most convenient, highly patient-compliant, cost-effective, and safe route of administration to treat various diseases [1]. Adequate intestinal absorption and oral bioavailability are the most critical pharmacokinetic parameters for successfully delivering oral drug candidates [2]. Since experimental in vivo determination of intestinal absorption and oral bioavailability parameters is only feasible in the late stages of preclinical development, in vitro cell cultures have long been used as a surrogate alternative for early detection and optimization of drug absorption.
Among the cell cultures developed for intestinal permeability screening, the Caco-2 cell line, stemming from the human colorectal adenocarcinoma cells, is one of the most widely accepted in vitro biological techniques [3]. However, its main drawback lies in the lengthy culture periods (3 weeks) and the associated high costs [4]. Machine learning in drug discovery provides a faster, more reliable, and cost-effective way of evaluating the Caco-2 permeability of drug candidates on a large scale. While many studies focus on developing machine learning models using open-source data, there is a lack of research involving models built on proprietary datasets [5].
In this work, we will develop a fingerprint-based model with Caco-2 data from both the GOSTAR™ small molecules database and a benchmarking open-source dataset, then examine the models’ predictive performance using advanced computational biology and AI-driven drug discovery approaches.
Materials and Methods
Datasets
For this study, experimental apparent permeability values were collected from the GOSTAR database and a curated benchmarking dataset integrating data from ChEMBL, DrugBank, PubChem, and BindingDB, developed by Wang et al. [6]. The same procedure was followed as outlined in our previously published methodology for retrieving data subsets from the GOSTAR database [7].
Once retrieved, all activity values in the GOSTAR Caco-2 dataset were converted to centimeters per second (cm/s), normalized using logarithmic scaling to compress the range, and filtered with cutoff values of LogPapp ≥ -7 and ≤ -3. Arithmetic mean values and standard deviations were calculated for compounds with multiple reported values to minimize uncertainty and account for experimental variability.
Only compounds with a standard deviation below one were retained, resulting in a dataset of 10,706 unique compounds for model training. The apparent permeability values in the benchmarking dataset were also converted to centimeters per second (cm/s) and normalized through logarithmic scaling. Once processed, no further modifications were made, and the resulting dataset, comprising 4,463 unique compounds, was used to train the model.
The activity distribution of both datasets is left-skewed, consistent with typical data published on Caco-2 apparent permeability (Figure 1).
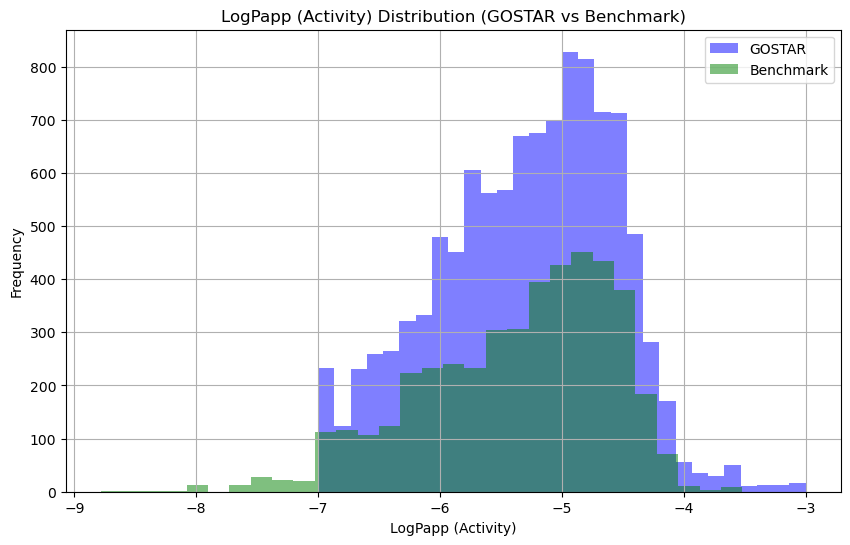
Figure 1. Distribution of Caco-2 permeability data between GOSTAR and benchmark dataset
Methodology
In this study, two stacking regressor models were developed to predict the permeability (LogPapp) of compounds using two different datasets: GOSTAR and Benchmark. Both models used molecular descriptors and fingerprints derived from SMILES notation as input features, supporting scalable data-driven drug discovery.
The models utilized two base regressors, ExtraTreesRegressor and XGBoostRegressor, with a LassoLarsCV linear model as the final estimator to combine predictions from the base models. Morgan fingerprints were generated from the molecular structure of each compound, while additional chemical descriptors, such as partition coefficient (LogP), topological polar surface area (TPSA), hydrogen bond donors (HBD), hydrogen bond acceptors (HBA), molar refractivity, number of valence electrons, number of double bonds, and other relevant molecular properties were computed to enrich the feature space.
After applying feature scaling, both datasets were split into training and test sets using an 80-20 random split.
Results
The models were evaluated using three key performance metrics: Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and the Pearson Correlation Coefficient (R), commonly used in predictive modeling for drug discovery informatics.
The GOSTAR-trained model demonstrated a 32% reduction in MSE, a 17% reduction in RMSE, and a 13% improvement in Pearson correlation. The model performed significantly better when trained on the GOSTAR dataset than the benchmark dataset. The Pearson correlation coefficient, which reflects the strength of the linear relationship between predicted and experimental apparent permeability values, improved substantially on the GOSTAR dataset, indicating that the model more accurately captured the permeability trends (Table 1).
| Metric | GOSTAR Dataset | Benchmark Dataset |
|---|---|---|
| Mean Squared Error | 0.19 | 0.28 |
| Root Mean Squared Error | 0.44 | 0.53 |
| Pearson Correlation Coefficient | 0.81 | 0.72 |
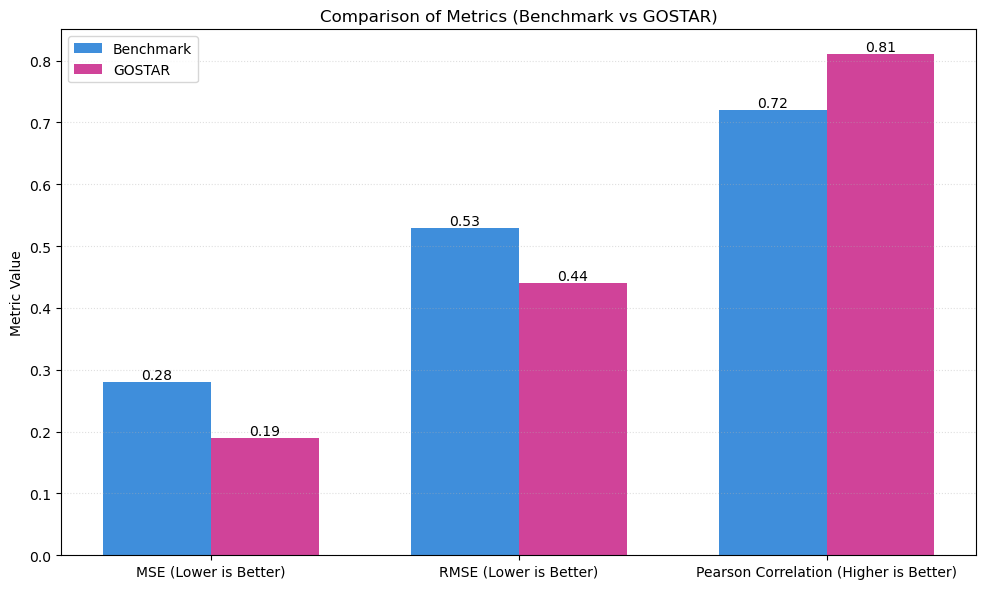
Figure 2. Comparison of model evaluation metrics between the GOSTAR and benchmark dataset
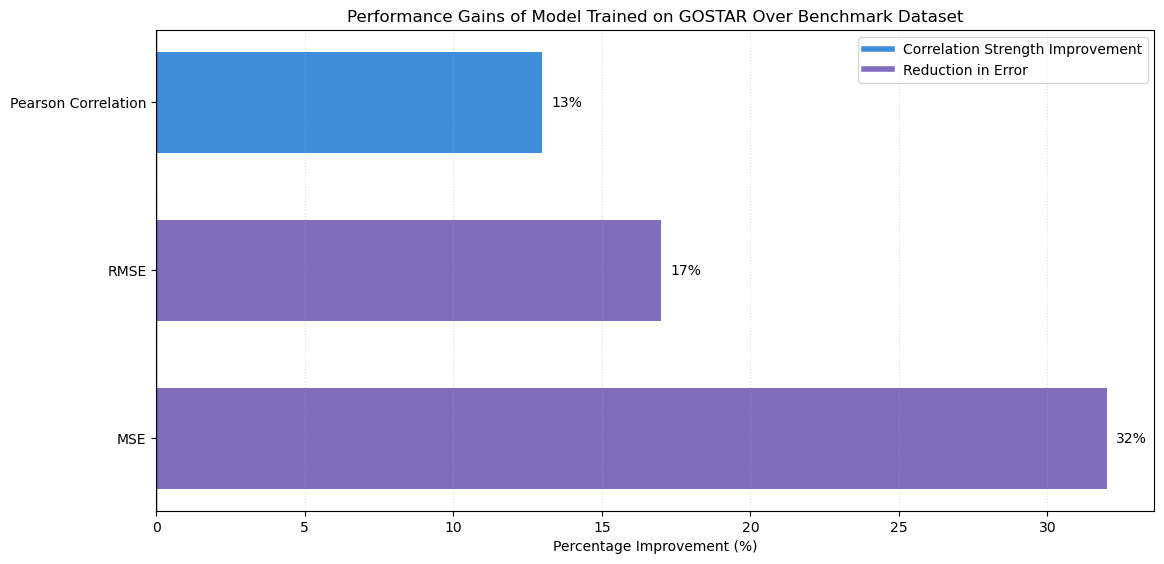
Figure 3. Comparison of performance gains between the GOSTAR and benchmark dataset
Conclusion
In conclusion, the stacking regressor, trained on the GOSTAR dataset, significantly outperformed the benchmark models in predicting permeability. The model’s improved accuracy, as evidenced by lower error metrics and higher Pearson correlation, underscores the GOSTAR dataset’s superior quality and diversity. This study highlights the importance of well-curated datasets like GOSTAR for developing robust and reliable predictive models in permeability predictions, cheminformatics, and pharmaceutical research informatics.
Reference
- Alqahtani, M. S., Kazi, M., Alsenaidy, M. A., & Ahmad, M. Z. (2021). Advances in Oral Drug Delivery. Frontiers in Pharmacology, 12.
- Lin, L., & Wong, H. (2017). Predicting Oral Drug Absorption: Mini Review on Physiologically-Based Pharmacokinetic Models. Pharmaceutics, 9(4), 41.
- Maeda, K., Suzuki, H., & Sugiyama, Y. (2008). Hepatic Transport. Methods and Principles in Medicinal Chemistry, 277–332.
- Delie, F., & Rubas, W. (1997). A Human Colonic Cell Line Sharing Similarities With Enterocytes as a Model to Examine Oral Absorption: Advantages and Limitations of the Caco-2 Model. Critical Reviews in Therapeutic Drug Carrier Systems, 14(3), 66.
- Dara, S., Dhamercherla, S., Jadav, S. S., Babu, C. M., & Ahsan, M. J. (2021b). Machine Learning in Drug Discovery: A Review. Artificial Intelligence Review, 55(3), 1947–1999.
- Wang, X., Liu, M., Zhang, L., Wang, Y., Li, Y., & Lu, T. (2020). Optimizing Pharmacokinetic Property Prediction Based on Integrated Datasets and a Deep Learning Approach. Journal of Chemical Information and Modeling, 60(10), 4603–4613.
- Selecting and preparing data for AI/ML predictive modeling. Excelra. https://www.excelra.com/whitepaper/selecting-and-preparing-data-for-ai-ml-predictive-modeling/ (accessed 2024-10-02).
Find out how Excelra’s GOSTAR can help your precision medicine projects and solve data-related challenges in drug discovery, pharmaceuticals, and healthcare.
