
Author: Ravi Teja Voruganti (Senior Technical Lead)
Introduction
In clinical programming, generating Analysis Data Model (ADaM) datasets is one of the most time‑consuming and repetitive tasks for statistical programmers. Each variable often requires a carefully written algorithm, validated logic, and a corresponding R program. As studies scale, so does the programming burden.
At Excelra, we asked a simple question: Can we automate this process without compromising accuracy or traceability? This aligns with Excelra’s broader AI and Machine Learning solutions designed to accelerate data-driven innovation across life sciences workflows.
The answer led us to build an AI‑powered ADaM Program Automation Tool—a system that uses Hybrid Retrieval‑Augmented Generation (RAG), vector databases, and large language models (LLMs) to generate high‑quality R code directly from a specification sheet. By combining FAISS‑based semantic search, Azure OpenAI embeddings, and a feedback‑driven learning loop, we created a solution that reduces manual effort, improves consistency, and builds a reusable knowledge base over time.
This blog walks you through how we built it, why it works, and how it can transform ADaM programming workflows.
Why automate ADaM programming?
Figure 1: Challenges in manual ADaM programming workflow
ADaM dataset creation is essential for regulatory submissions, but the process is often:
- Manual
- Repetitive
- Dependent on programmer experience
- Prone to inconsistencies across studies
A typical workflow requires programmers to interpret specifications, derive algorithms, write R code, validate outputs, and maintain documentation. When multiple studies run in parallel, this becomes a bottleneck.
Automation helps us:
- Reduce programming time
- Improve consistency across studies
- Minimize human error
- Free programmers to focus on complex derivations and validation
- Build reusable institutional knowledge
Such automation approaches complement Excelra’s Clinical Data Services, which focus on transforming raw clinical information into analysis-ready datasets for regulatory and research workflows. Our goal was not to replace programmers, but to augment them with a system that handles the repetitive parts reliably.
Building the vector database for ADaM knowledge
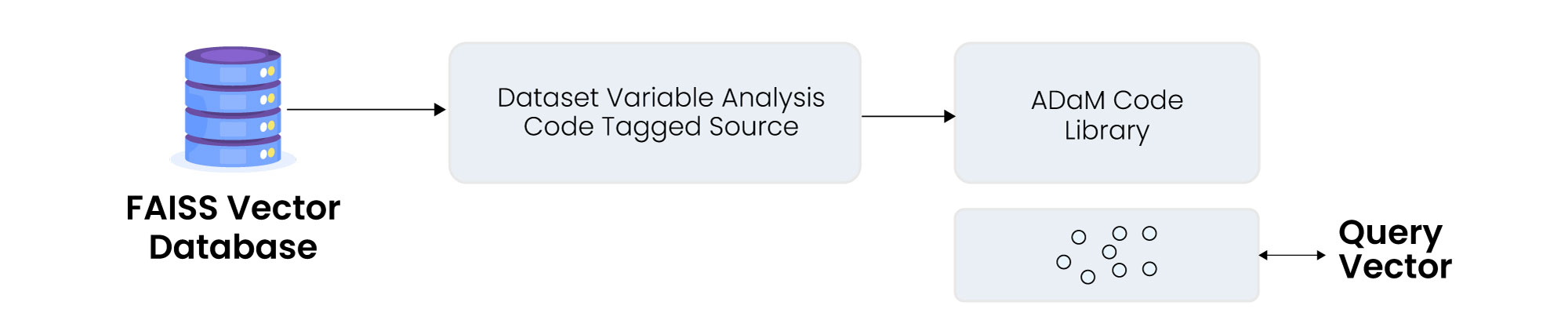
Figure 2: Challenges in manual ADaM programming workflow
The foundation of our automation tool is a vector database (VDB) built using FAISS, an open‑source library optimized for similarity search. Similar scalable data architectures are central to Excelra’s Scientific Data Management capabilities, enabling efficient handling of complex scientific and clinical datasets. We embedded 195 curated ADaM code library entries—each containing:
- Dataset
- Variable
- Analysis algorithm
- Revised algorithm
- R code
- Tagged source
To generate embeddings, we used the text‑embedding‑3‑large model from Azure OpenAI. Each row was converted into a semantic vector representing its meaning, not just its text.
Why a vector database?
Traditional keyword search fails when:
- Variable names differ slightly
- Algorithms are phrased differently
- Context matters more than exact text
Vector search solves this by retrieving the closest semantic match for any query. For example:
Query: “ADEG ADY Copy from ADEG.ADY”
The VDB returns the most relevant ADaM logic—even if the wording differs.
These intelligent automation strategies are closely aligned with Excelra’s Data Science Services, where advanced analytics and AI models are applied to solve complex biomedical challenges. This forms the backbone of our Hybrid RAG approach, where we combine:
- Retrieval (FAISS + embeddings)
- Generation (LLM‑based algorithm and code creation)
The Two‑Step AI workflow for R code generation

Figure 3: Two-step AI workflow for ADaM R code generation
Our automation pipeline runs in two major steps.
Step 1: generate the revised algorithm using hybrid RAG
For each row in the specification sheet (Dataset, Variable, Analysis Algorithm), we:
- Construct a semantic query
- Retrieve the closest match from the VDB
- Inject the retrieved context into a structured prompt
- Ask the LLM to generate a Revised Algorithm
This ensures the algorithm is:
- Aligned with ADaM standards
- Context‑aware
- Consistent with historical logic
- Adapted to the specific variable and dataset
This step dramatically reduces ambiguity and ensures the generated logic is grounded in prior validated code.
Step 2: generate R code from the revised algorithm
Once the revised algorithm is ready, we feed it into a second LLM prompt designed to produce:
- Clean
- Modular
- Readable
- Study‑ready
R code for the variable.
The generated code is saved as an .R file in the POSIT Workbench environment and is ready for integration into the study pipeline. Integrating automated pipelines into enterprise environments reflects Excelra’s expertise in Cloud Enablement, supporting scalable and secure deployment of scientific applications.
Closing the loop — Learning from every run
One of the most powerful features of our system is the feedback loop.
After generating the R code:
- We embed the new code
- Append it to the vector database
- Store metadata including function name and timestamp
This means the system learns continuously.
Over time:
- The VDB becomes richer
- The LLM relies less on generation and more on retrieval
- Costs decrease
- Accuracy increases
- Study‑specific logic becomes part of the institutional memory
This transforms the tool from a one‑off automation script into a self‑improving knowledge engine.
Technical architecture overview

Figure 4: Technical architecture diagram of ADaM automation tool
Here’s a simplified view of the architecture:
1. Input layer
- Excel specification sheet
- Dataset, Variable, Analysis Algorithm
2. Embedding layer
- Azure OpenAI embeddings
- FAISS vector normalization
- Semantic indexing
3. Retrieval layer
- Vector search for closest match
- Context extraction
4. Generation layer
- LLM prompt for revised algorithm
- LLM prompt for R code
5. Output layer
- R program saved to POSIT Workbench
- Updated VDB with new embeddings
- Metadata appended with function name and timestamp
6. UI layer
- Streamlit interface for user interaction
- Real‑time logs and outputs
This modular design ensures scalability, maintainability, and transparency.
Benefits for statistical programming teams

Figure 5: Technical architecture diagram of ADaM automation tool
Our automation tool delivers measurable value:
1. Significant time savings
Automating repetitive derivations frees programmers to focus on complex logic and validation.
2. Improved consistency
Algorithms and code follow standardized patterns across studies.
3. Reduced cost
The feedback loop reduces LLM usage over time, lowering operational costs.
4. Enhanced traceability
Every generated function is timestamped and stored with metadata.
5. Scalable knowledge base
The VDB grows with every run, capturing institutional expertise.
6. Seamless integration
Hosted on POSIT Workbench with a Streamlit UI, the tool fits naturally into existing workflows.
Conclusion
Automating ADaM programming is no longer a futuristic idea—it’s a practical, scalable solution that brings immediate value to statistical programming teams. By combining Hybrid RAG, vector databases, FAISS search, and Azure OpenAI models, we created a system that generates accurate R code, learns continuously, and reduces manual effort dramatically.
This approach doesn’t replace programmers—it empowers them. It ensures consistency, accelerates delivery, and builds a reusable knowledge base that strengthens over time. Learn how Excelra applies similar AI-driven approaches through its Excelra for AI initiatives focused on accelerating discovery, automation, and digital transformation in life sciences.
As we continue refining this platform, we’re excited about its potential to transform clinical programming workflows and support faster, more reliable study execution.
If you’d like to explore how this solution can be adapted for your organization, we’d be happy to discuss it with you.
