Overview
Post-translational modifications (PTMs) play a critical role in regulating protein function, signaling pathways, and disease mechanisms. Among these, SUMOylation represents an important modification influencing transcriptional regulation, protein localization, and cellular stress responses. However, publicly available SUMOylation information exists across fragmented databases and scientific literature, creating challenges for systematic analysis and target discovery.
To address this challenge, Excelra developed a text-mining-based integrated PTM database using advanced Data Curation Services, Scientific Informatics, and scalable Bioinformatics Solutions. The initiative enabled structured knowledge mining aligned with modern FAIR data principles for life sciences research.

Our client
A US-based biotechnology company partnered with Excelra to build an integrated knowledgebase focused on SUMOylation — a post-translational modification of significant biological interest. The organization required a centralized resource combining internal research data with publicly available biomedical datasets to support downstream landscape analysis and target identification workflows.
The project aligned with broader industry trends toward data-driven biomedical research and digital transformation in drug discovery.

Client’s challenge
The client faced several key challenges:
- SUMOylation data was highly scattered across multiple public databases and literature sources.
- Lack of standardized terminology and controlled vocabulary limited effective analysis.
- Public and proprietary datasets required integration into a structured framework before any landscape assessment or target discovery could be performed.
- Manual compilation of PTM information was time-intensive and prone to inconsistency.
As shown in the workflow description in the case study document, large-scale literature mining and structured variable generation were essential prior to database development

Client’s goals
The client aimed to:
- Develop an integrated database for SUMOylation from publicly available databases and literature.
- Collate, standardize, and harmonize PTM information.
- Create a structured lexicon supporting SUMOylation research.
- Enable downstream landscape analysis and target identification.
- Establish a scalable foundation for future biological knowledge mining.
These objectives aligned with approaches described in text-mining and biomedical knowledgebase development initiatives.
Our approach
Excelra implemented a structured scientific informatics and biocuration workflow.
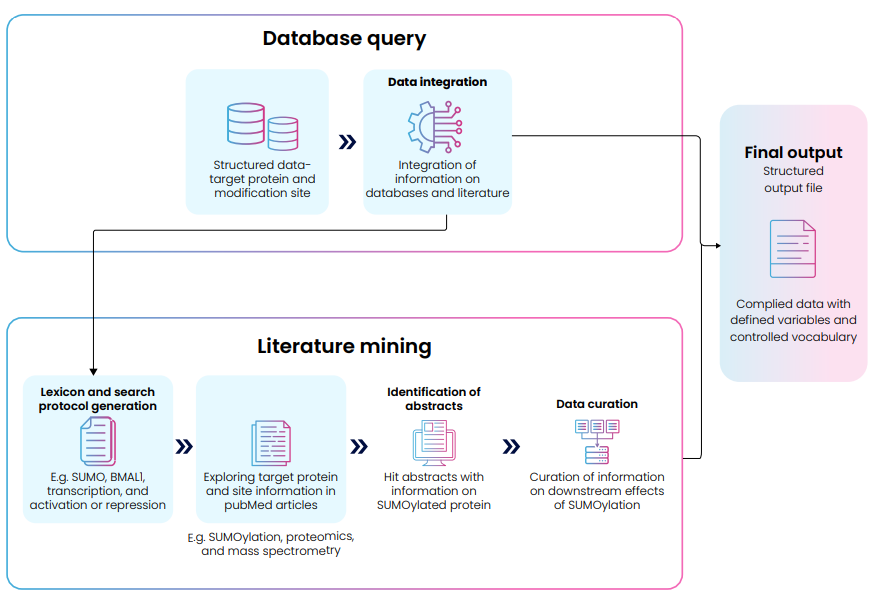
Literature mining & lexicon development
Excelra developed a SUMOylation lexicon using proprietary text-mining algorithms to identify relevant literature and databases. Millions of articles were screened, and during the pilot phase, 100 full-text articles covering ~22 SUMOylation-mediating enzymes were selected from PubMed Central
Data collation & variable generation
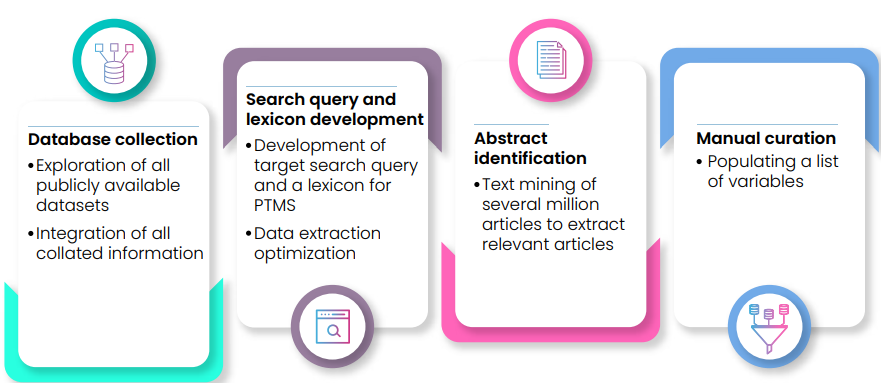
The workflow included:
- Database identification and exploration
- Search query development
- Abstract identification through literature mining
- Manual biocuration
- Structured variable population
This process followed Excelra’s established Semantic Data Services and ontology-driven integration approaches supported by ontology and FAIR data frameworks.
Data standardization & integration
Curated information from literature and PTM databases was integrated using UniProt identifiers and SUMOylated amino acid positions, ensuring standardized biological annotation.
Scientific platform enablement
Excelra leveraged expertise in:
- Scientific Application Development
- Computational Biology Services
- Structured Scientific Data Management workflows
to enable scalable database deployment and downstream analytics.
Our solution
Excelra successfully delivered a high-quality, text-mining-driven PTM database for SUMOylation research.
Key Outcomes
- Identification and integration of SUMOylation data from 27 PTM databases into a unified structured framework
- Creation of a standardized SUMOylation lexicon.
- Quality-assured biocuration combining automated text mining with expert manual validation.
- Development of a structured output dataset enriched with curated variables and controlled vocabulary.
- Accelerated landscape analysis, hypothesis generation, and target discovery workflows.
The resulting system enabled analysis-ready datasets similar to Excelra’s broader work in analysis-ready data generation for AI-driven drug discovery.
Conclusion
This case study demonstrates the importance of combining text mining, scientific informatics, and expert biocuration to unlock value from fragmented biomedical data sources.
By integrating large-scale literature mining, ontology development, and structured data management, Excelra enabled the creation of a reliable SUMOylation PTM knowledgebase supporting advanced biological research and target identification.
The project highlights Excelra’s capabilities in building scalable biomedical knowledge platforms through:
- Data curation
- Bioinformatics analytics
- Scientific data management
- Computational biology workflows
Together, these capabilities support modern drug discovery initiatives powered by AI-enabled life sciences solutions.
Learn more about Excelra’s expertise via Our Services or connect with our experts.
