
Life sciences companies invest billions in AI, but most projects fail to meet goals. The main obstacle is poor data prep, not the models. The bottleneck in pharma AI impact is data quality across the drug discovery-to-development chain. Success depends on trustworthy, connected, reusable data products, not scattered files or ad-hoc integrations.
Value-Chain Readiness Heatmap
| Semantics | Lineage | Automation | Governance | |
|---|---|---|---|---|
| Target & Hit ID | A | A | A | A |
| Lead Optimization | A | R | A | A |
| Preclinical & CMC | R | A | R | A |
| Clinical (I–III) | A | R | A | A |
Legend: R = Low readiness, A = Partial, G = Strong
What stakeholders struggle with (by value-chain stage)
- Target & Hit ID: siloed assay and omics data; weak metadata prevents cross-study reuse.
- Lead Optimization: poor traceability from ELN/LIMS to analytics; manual transformations slow cycles.
- Preclinical & CMC: instrument/proprietary formats block harmonization; lineage gaps undermine credibility.
- Clinical (I–III): fragmented sources complicate evidence synthesis; auditability and FAIR gaps delay decisions.

Why these problems persist?
- Inside-out tooling vs. value-chain outcomes: systems optimized per lab/app, not decision flows.
- Proprietary formats & legacy integrations: 60–80% of effort still spent preparing data, not analyzing it.
- Inconsistent metadata & governance: variable schemas and ownership; reproducibility at risk.
- Retrofit reality: replacing platforms is costly; “glue code” accrues tech debt.
What good looks like?
- Value-chain-aligned data products: well-modeled entities (assays, samples, batches, protocols) with versioning & lineage.
- Harmonized semantics: controlled vocabularies/ontologies; FAIR by default across labs and studies.
- Automated data journey: instrument→SDMS/warehouse→analytics with QC gates and audit trails.
- Cloud-native, governed platform: role-based access, catalogs, and continuous quality monitoring.
How we get you there? (Excelra approach)
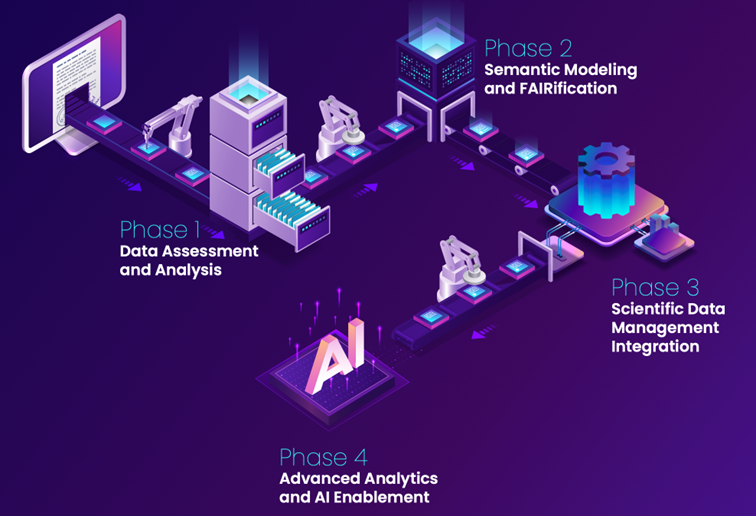
Business outcomes to expect:
Faster Cycles
Materially shorter time from data capture to decision readiness in preclinical and CMC
Higher Reuse
Fewer repeats; better cross-program comparability
Regulatory Credibility
Evidence & lineage packaged for regulatory review
Lower total cost
Less manual wrangling; more analyst/scientist time on science
Download the whitepaper to uncover how life sciences companies can overcome data bottlenecks and build AI-ready data across the entire drug discovery-to-development value chain.
