
Genesis of the concept of FAIRification
The information age (mid-20th century onwards) witnessed a boom in data generation and digitization. The current century is an era of not only data creation but also data analytics which yields the true value of data. The effective utilization of the data to enhance value for all is an evolving concept which resulted in the inception of ‘FAIR’ data practices. FAIRification comprises of 15 guiding principles outlined by Wilkinson et al (2016) which are aimed at enhancing the findability, accessibility, interoperability and reusability of data. It is a way of connecting and harnessing the power of data being generated to maximize its utility.
Each principle has a core set of values which reflect its utility. The Findability principle assigns the data/metadata a universality providing recognition for research. Accessibility operates on accountability. It reflects the openness amongst the data providers to provide access to the data. Interoperability provides ease and equal accessibility to the data. Reusability empowers multiple uses of the data thereby increasing its impact. With these core values FAIRification can have a significant positive impact on the mindset of the data creators, making the community more inclusive for a more meaningful utilization of data2.
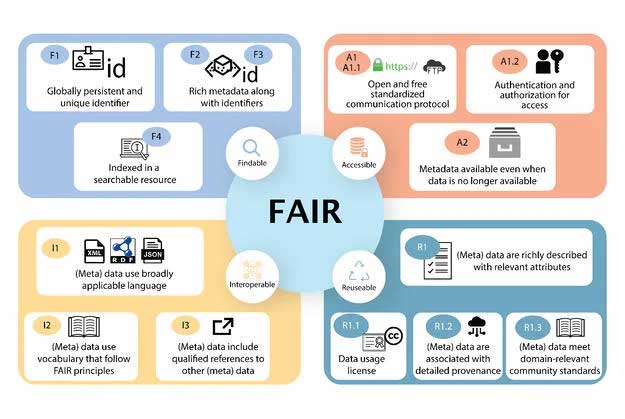
Figure 1: FAIR guiding principles as outlined by Wilkinson et al 20161
Need of the hour (Challenges, Necessity and Current approaches)
Conventionally, data lakes and data warehouses were constructed to manage and disseminate high-quality data consistently and with ease. Protected, siloed data however turned out to be a major impediment to knowledge discovery and innovation among relevant stakeholders. Lack of community standard ontologies to normalize heterogenous data, high costs and intense efforts incurred to regulate digital processes and resources, also proved to be key challenges to productivity and cross-domain collaborations. Need of the hour was to enable efficient data management, governance and availability. Implementation of the FAIR guiding principles results in breaking down data silos that will make make data available to both humans and machines.
Aligning FAIRified data is needed at multiple levels with high priority for:
- Unlocking scientific transformation – Adopt a work force culture shift from ‘my data’ to a ‘corporate’s valued asset‘ and spawn FAIR data sharing amongst multiple benefactors for data transformation. Scientific queries will be answered more rapidly in an ad hoc and flexible manner.
- Reducing expenses – As per a recent EU report, not having FAIR data costs an estimated €10.2bn/year to the European economy3. Hence, FAIRification is urgently required to reduce costs and risks towards data discovery, enhance rewards, and generate long-term return on investment (ROI).
- Increasing strategic value addition – Harness the power of AI/ML on FAIR data to accelerate the creation of new, valuable data assets and associations. The time across the value chain from R&D to outcomes will significantly reduce, productivity will increase and drug pipelines can be accelerated.
- Minimize data wrangling – The time, price, and effort invested in gathering, selecting, cleaning, and transforming raw data into high-quality, standardized analysis-ready formats could be decreased by using FAIRified data.
FAIR principles are anecdotal and act as guidelines in the FAIRification process. The current approaches evaluate FAIRness through crucial maturity indicators and quantifiable metrics applied to data, metadata, and associated infrastructure4. Scoring for findability and accessibility is attained at the metadata level in one go, but assessment of interoperability and reusability might entail intensive iterations. The FAIRification process can be broadly categorized into the following steps:
- Retrieve non-FAIR data: Access data to be FAIRified
- Analyze retrieved data: Examine data content with respect to concepts, structure, relationships between different data elements, different data identification methodologies and analysis, provenance, etc.
- Define semantic model for data: Use community, purpose, and domain-specific ontologies and controlled vocabularies to describe and define dataset entities, concepts, and relations in an accurate, unambiguous and machine-actionable format
- Make data linkable: The non-FAIR data can be transformed into linkable data by applying the semantic model defined in step 3 using Semantic Web and Linked Data technologies. This ensures interoperability and reuse, facilitating the integration of the data with other types of data and systems
- Assign license: Ensure data license information is included, else reuse of data might get hampered
- Define metadata for the dataset: Ensure that the data is described by proper and rich metadata to support all aspects of FAIR data assessment
- Deploy FAIR data resource: Deploy or publish the FAIRified data, together with relevant metadata and a license, so that the metadata can be indexed by search engines and the data can be accessed, even if authentication and authorization is required.

Figure 2: FAIRification workflow adapted from GO FAIR4.
Utility and benefits
The benefits of FAIRifying data are multi-pronged. For research communities, the obvious benefits include seamless data acquisition, semantic calibration, integration and data analytics5. This has multi-fold utility in terms of cutting down research and development time and promoting a virtual knowledge network amongst the scientific community. This leads to significant advances in the knowledge of domains in a relatively short period of time. The benefits to the biopharmaceutical sector are huge as well. These include reduced time for drug discovery due to data sharing and clear data reuse policies across the sector, increased innovation in personalized medicine by use of real-world data and availability of high-quality data for AI/ML based analytics.
From the point of view of business, the impact is three-fold namely; financial, operational and customer oriented6.
- Financial impact: A study by Barua A et al measuring the impact of effective data on business shows that upon improving the usability of data by a mere 10% there is an estimated increase in sales per employee by 14.4%. Also, reduction in the effort and time to make data useful for the user results in a significant improvement in the productivity per employee6.
- Operational impact: It involves effective utilization of assets, accurate planning and forecasting6.
- Customer-oriented impact: It results in a better ability to innovate in relatively short periods of time6.
Thus, processes like FAIRfication which are intimately involved in improving data sharing and usability would have an overall long-term positive impact on business6.
These benefits are now being recognized across sectors and many organizations are investing time and effort towards FAIRification with a long-term astute goal in mind.
Excelra’s approach
Excelra understands the importance and the value thereof of FAIRifying data. Evaluating FAIRness is the fundamental step towards FAIRification. Considering the benefits to the biopharmaceutical sector, as a first step Excelra has devised a streamlined process with a customizable questionnaire and standard operating procedure (SOP) for evaluation of a given database for its compliance to the FAIR principles. Databases and their associated data and metadata are assessed by domain experts. A specialized quantitative assessment assists our partners to better understand the extent of compliance. A detailed report along with recommendations is provided to understand the steps for better compliance to the FAIR guidelines.
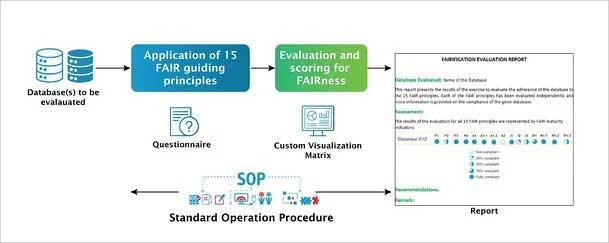
Figure 3: Schema for FAIR evaluation of a given database.
Case study
As a first step towards understanding the FAIRness of the existing databases, 12 public databases covering proteins, drugs, genes, pathways and diseases were evaluated for their compliance to the FAIR principles. The assessment was based on the methodology developed by Excelra elaborated in the previous section. The databases assessed are enlisted below-
- Proteins– PDB, Binding DB, UniProt
- Drugs/Chemicals entities– PharmGKB, ChEMBL, PubChem, DrugBank
- Genes– NCBI Gene, Ensembl, GWAS catalog
- Pathway – Reactome
- Diseases– DisGeNET
The questionnaire and SOP were extensively utilized for scoring and evaluating each database. Based on the assessment and scoring the results were collated.
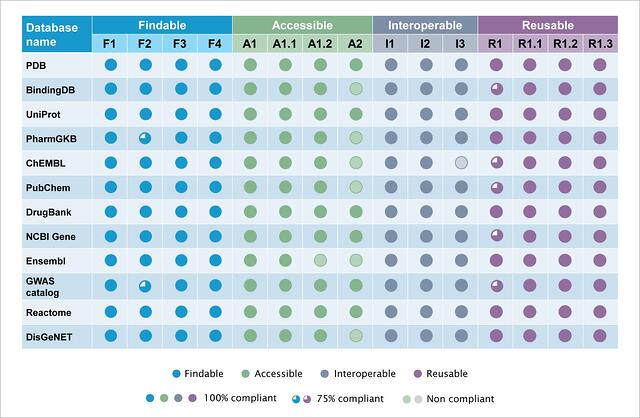
Figure 4: Summary of the quantitative assessment of 12 public databases for FAIR compliance.
Salient features from the analysis are:
- All databases are compliant to >13 of the 15 principles.
- All the databases irrespective of their themes have relevant descriptive metadata elements incorporated. These are usually compliant to the FAIR principles related to metadata and their associated identifiers.
- Findable- The 12 databases evaluated are public and are compliant to the ‘Findable’ principle. PharmaGKB and GWAS catalog are partially compliant to F2 as they lack certain metadata types.
- Accessible- Most databases evaluated, have data dumps accessibility. These are compliant to the ‘Accessibility’ principle. However, 5 databases are not compliant with the A2 principle. This principle discusses the availability of metadata even after the data is no longer available. This indicates that some databases do not make versions of their databases available. Lack of retrospective data and or lack of evidence of the existence of data leads to A2 non-compliance.
- Interoperable- Databases evaluated in the current study show compliance to the principles of ‘Interoperability’. ChEMBL however, is not I3 compliant as the chemical entity output does not include references to related metadata
- Reusability- Certain databases are partially compliant to R1. It is observed that the ‘About’ page of these databases do not provide all the requisite information. All the databases are compliant with the R1.1, R1.2 and R1.3 principles.
FAIR being a new evolving concept which has come up in the past decade, many databases are yet to be fully FAIR compliant. Although it is observed that most databases in the life sciences domain frequently utilized by both academicians and in industries are mostly FAIR compliant. The extensive use of these and their proven utility across years is also a proof to how being FAIR compliant has helped them.
Excelra’s edge
The key differentiators that set Excelra apart from other experts in FAIRness evaluation can be summarized in the following points:
- Excelra holds 18+ years of experience in data sciences with 60+ PhDs in 600+ talent pool. We are associated with 90+ clients across the globe and provide expert support in various capacities to 15 of the top 20 pharma companies
- The organization is equipped with data, deep domain expertise and data science capabilities
- Vast experience in related services including but not limited to Data curation, Data annotation, Data validation, Ontology management, Data wrangling, Data management & integration
- Domain experts are well-acquainted with diverse range of data types from Discovery to Real World from various data sources
- Excelra possesses wide variety of in-house data analysis tools
- Excelra is well versed in delivering tailored end-to-end database solutions to various pharma, biotech, healthcare and AI/ML companies
- Finally, the presence of a multidisciplinary blend of Math, Computation, and Life Sciences expertise under one roof enables Excelra to offer customized FAIRification solutions with a quick turnaround time
Future outlook
FAIRifying data will thus, accelerate data driven scientific and knowledge discovery. By adopting FAIR data, the scientific and industrial communities will be able to capitalize on the benefits of new age technologies such as AI/ML in further reducing cost and time.
