
What to consider when looking for a source of biological data for your biotech start-up?
Public and commercial biological data repositories are interesting sources of external data because they allow biotech start-ups to test and validate their initial R&D concepts relatively quickly and cost-efficiently. Since this testing can take place before a start-up acquires its own data or as a supplement to such data, the public, and commercial resources can greatly accelerate the start-up’s growth. In his blog post, we discuss the differences between the various data sources and what to consider when choosing one.
Proving a start-up idea viable is one of the most critical prerequisites to getting the start-up off the ground with the initial funding opportunities. In the case of many biotech and life science start-ups, the development of such proof of concept (PoC) requires data, for example, the genetic information of patients with a specific type of cancer. At an early stage, however, most start-ups don’t have their data yet or their sample size is too small to provide statistically relevant results. Without funds to establish a wet lab, it is also difficult to generate their own data. To break this vicious circle, start-ups can leverage the already existing data from external sources.
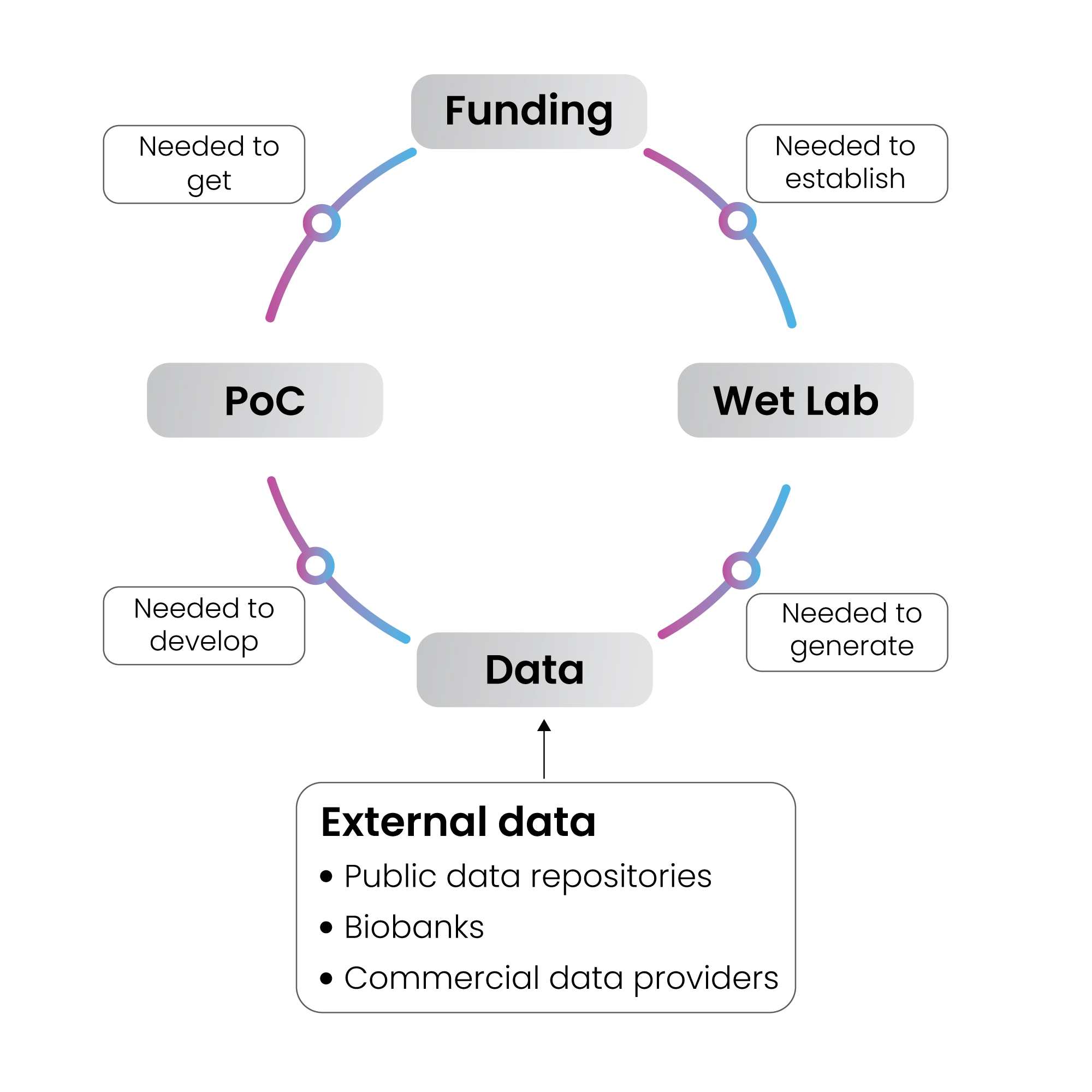
There are three major types of external data sources:
- public data repositories
- biobanks
- companies specialized in collecting and analyzing bio and clinical data
Let’s review how and when each of them can best help a biotech start-up and what are the potential drawbacks.
What are public data repositories?
The publicly accessible repositories of biological data are online databases where scientists are depositing their research data, software, and code. Most of the time, this data doesn’t contain any sensitive information. Many public data repositories are discipline-specific, for example, the European Genome-phenome Archive EGA (genomics), BioModels Database (mathematical and modeling resources), and Image Data Resource (imaging). There are also several cross-disciplinary generalist repositories, for example, Dryad Digital Repository, figshare, and Harvard Dataverse Network.
Check the overviews of the established and trusted repositories, listed on Nature and PLOS.
Depending on the field, our team recommends European Nucleotide Archive (ENA), Sequence Read Archive (SRA), Genomic Data Commons (GDC). Lesser known, but important regarding diversity and research of rare diseases are MalariaGEN (related publication), 1000Genomes (related publication) and H3Africa (related publication).
Leading scientific publishers encourage or even oblige researchers to deposit resources that support findings reported in the works submitted for publication. This requirement is often also an inherent element of research consortiums.
Pros and cons of using public data repositories
Most of the repositories don’t ask for justification of the need to access data, therefore this way of getting the resources is the fastest. Moreover, there is no charge for accessing the data, which might be an appealing point, especially for start-ups with a small budget. These advantages come however with a major downside which is the often relatively low quality of the data. Frequently, there are no clear standards or structures regarding what type of data and in what format should be deposited. Also the metadata, for example, information on how a sample was processed or how well-balanced the dataset is, might be incomplete. Furthermore, because the data usually comes from research projects, the resulting sample sizes are rather limited.
The use of public data by a start-up is therefore worth considering mostly when there is time pressure to kick off the /in silico/ R&D. The data might be useful to set up pipelines and, with a bit of luck, the initial results can already give valuable insights, help develop a rudimentary PoC and guide the follow-up analyses with data of better quality. As discussed below, getting data from biobanks might take a while and instead of idly waiting, start-ups can use this time to move forward. Also, if a start-up has some initial data, it can supplement them with public data. In this way, it can gain more credibility and strengthen its case or even extend its initial PoC from one organism (for example mice) to another organism (for example humans).
Pros:
- (usually) no application (instant access) / saves time
- (usually) free / saves costs
Cons:
- the quality of the data might be relatively low
- metadata might be incomplete
- usually small sample sizes
What are biobanks?
The term ‘biobanks’ refers to a wide range of organizations that collect, process and store biological/medical samples and related data in an organized system. Biobanks are often affiliated with healthcare institutes and universities, which might also serve as samples and data sources. One of the important contributions to the development of biobanks in recent years has undoubtedly been advancement in the various omics fields. The popularity of biobanks measured as the number of references to “biobanks” or “biobanking” in the PubMed database showed a 4-fold increase from 2015 to 2020. There are more than 120 biobanks worldwide.
Pros and cons of using biobank data
In comparison with public data repositories, biobanks offer a couple of advantages. Thanks to their stringent standards regarding formats and content of the data and metadata, biobanks usually provide well-curated, high-quality, and complete datasets. The data originates moreover often from large study cohorts which enhances confidence in the results.
This last point might be particularly interesting for start-ups working in the domain of rare diseases, as in this case, public repositories have very little data to offer.
Using data from well-known and trusted biobanks comes with another important benefit – it adds extra credit to the start-up’s R&D, raises its authority, and makes it more reliable and trustworthy. It is not unheard of that VC companies actually ask to verify a start-up R&D concept using data from a leading biobank. Start-ups with a good story backed by solid data from an established and respected biobank have moreover a higher chance of attracting the best talents.
Similar to public data repositories, biobanks do not charge for access to their data. Start-ups need to take into account however that the application process might cost them a significant amount of time. While biobanks have collections of samples and data from various biological species, usually those of human origin are of special interest (i.e. clinical data studies, human trials). Because such data often contains sensitive information, accessing the data follows an official application process. Its format and content differ between biobanks, but one has to be prepared to provide a project proposal, including for example a detailed description and goals, information on who will be involved in the project, how the infrastructure used will assure adherence to required criteria of data security, etc. Preparation of the application is not trivial and might take a considerable amount of time. The processing of the application is often not fast either and there is no guarantee that it will be approved.
Using data from biobanks is, therefore, a better solution for start-ups that need high-quality and large-sample data, but can afford to wait for access.
Pros:
- (usually) free
- (usually) well-curated, complete, and high-quality data
- large-scale study data increase confidence in the results
- data from trusted biobanks increase the authority of the start-ups
- R&D idea
Cons:
- preparing a proposal is time-consuming.
- getting the data might take a long time (even a few months)
Need professional help to prepare an application for a biobank?
Our experts continuously support start-ups in this process. Request our help now.
A special case: dbGaP
The database of Genotypes and Phenotypes, dbGaP, is a mix of a public repository and biobank. Created by National Center for Biotechnology Information (NCBI), this database contains both open-access as well as restricted-access data. The publicly available repository is called Sequence Read Archive (SRA) and contains high throughput sequencing data, usually acquired for mice or other model organisms, though sometimes it also provides human data from research studies. Much of the human data is however only accessible in an application process, similar to biobanks. Still, coming from NIH, even this restricted-access data in dbGaP mostly originates from research studies and usually presents smaller sample sizes. Also, the dbGaP standardization level of the acquisition, preservation, storage, processing and analysis of samples is not as high as in the case of biobanks.
What are commercial suppliers of biological data?
A third potential source of biological data is companies that specialize in biospecimen collection. Usually, they offer biospecimen that a purchaser can process and analyze on their own, but many of them provide also sample processing services, such as sequencing, and deliver data that can be further explored just as in the case of data from public repositories and biobanks.
Pros and cons of using commercial suppliers of biological data
The major advantage of this option is that the data is well-curated and of high quality. The application process takes about 1-3 weeks of preparation, depending on the number of data sets. The speed of response and gaining access to the data varies between the different providers.
Since it is a paid option, it is worth considering for start-ups with an available R&D budget.
Pros:
- well-curated data
- possibility to customize the type and amount of data
Cons:
- not free
To sum up, using external sources of biological data is an excellent way for biotech start-ups to validate their first R&D ideas or explore alternative development paths without having to acquire the necessary data themselves. This approach can save a lot of time and money and facilitate the growth of the new venture. Public data repositories, biobanks, and commercial suppliers of biological data are the three major sources of external. They differ in data quality, access procedures, time and costs it takes to get the data, etc. Start-ups that need external data have therefore the option to choose a source that best fits their current situation.
