
Key aspects of building a predictive analytics engine are closely tied to the growth in computational power and the rapid expansion of Big Data. Data management has been the cornerstone of this technological evolution, enabling organizations to save time, reduce costs, and optimize effort. These efficiencies allow enterprises to focus on more complex challenges using big data analytics and advanced predictive technologies.
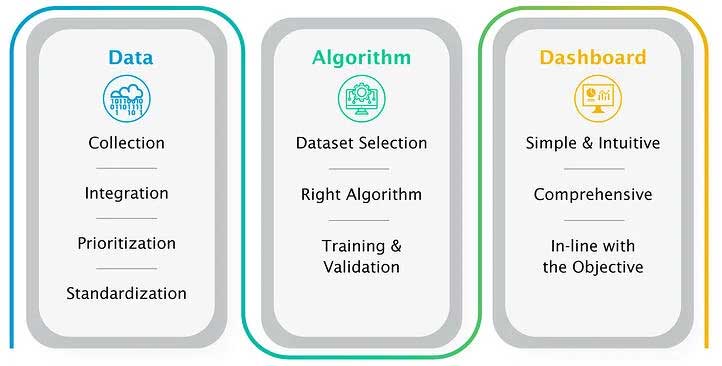
Figure 1: Key aspects of building a Predictive Analytical Platform
How to build a predictive analytics engine
Building a predictive analytics engine entirely depends on its foundation, namely the data and the subsequent processes involved. Due to the sequential nature of the workflow, it becomes imperative to be cautious at each step, as an error at any stage can affect overall prediction quality. From data preparation and predictive analytics algorithm selection to defining the front-end user experience, multiple factors influence the success of a predictive analytics platform.
This article highlights the essential rules that must be considered while building a predictive engine.
Data handling
The freedom of information on the internet has accelerated innovation, but it also raises concerns about data authenticity. Identifying reliable and trusted data sources is the first critical step in data-driven predictive modeling. It is advisable to source data from reputed organizations dedicated to maintaining accuracy and quality.
Extraction
The extent of data available from a source depends on the objectives of the data-holding organization, which may or may not align with your requirements. In such cases, extracting data from multiple sources ensures adequate data size and quality. Techniques such as web scraping, data mining, and parsing are commonly used, alongside manual curation when required.
Integration
Integrating data from multiple sources into a unified environment can be challenging. Preserving source-specific data patterns is essential to maintain relationships between variables. This step enables a holistic understanding of data dimensions and strengthens data management for analytics.
Prioritization and feature selection
Often, data repositories provide full data dumps instead of selective downloads. Identifying and retaining only relevant variables helps eliminate noise and enhances the performance of the predictive analytics engine.
Standardization
Standardization involves analyzing data distribution to detect skewness or outliers. Fine-tuning data ensures unbiased model behavior and consistent user experience across the platform.
Algorithm selection
Modern intelligent systems are driven by algorithms. Selecting the right algorithm based on the objective is critical, as no single algorithm performs optimally across all scenarios. In some cases, custom algorithms combining multiple statistical techniques may be required. Selecting an unbiased, representative training dataset is essential to ensure reliable predictions and concept validation.
Dashboard development
Dashboard development is the final yet crucial step in building a predictive analytics engine. The user interface should be intuitive, interactive, and visually balanced to enhance trust and usability. Testing across multiple screen resolutions and environments ensures a seamless user experience.
Case Study
Objective
The manufacturing and use of chemicals significantly support modern society, but workplace safety is critical, especially in pharmaceutical manufacturing environments. Excelra supported a leading pharma company by developing a predictive analytics engine to estimate Occupational Exposure Limits (OEL) and hazard information for known and unknown compounds, ensuring employee safety and regulatory compliance.
Approach
A web-based application was developed by integrating multiple datasets containing OEL values and hazard information. Due to sparse public data and regional variations, extensive data harmonization was performed while preserving original relationships. Unit of Measurement (UoM) normalization ensured consistency across datasets.
Geographical variations in OELs were retained to enable region-wise hazard assessment. Compound-centric data was sourced from public repositories and Excelra’s proprietary SAR database. Automation and manual curation techniques were applied to create a uniform data structure.
This dataset powered a structural similarity algorithm capable of predicting OEL values for new compounds or classifying them into industry-standard toxicity categories. Rigorous validation minimized false-positive and false-negative predictions.
Solution
The predictive analytics engine enables users to query chemical substances using SMILES notation or structural drawings. The platform predicts OEL values and recommends appropriate handling environments, supporting occupational health and safety when public data is limited.
The excelra edge
Excelra builds advanced analytics solutions grounded in strong data foundations, robust algorithms, and intuitive front-end design. Our multidisciplinary teams comprising data scientists, chemists, biologists, and UI experts collaborate seamlessly to deliver high-quality predictive analytics engines.
Our capabilities span data science and analytics, data management solutions, knowledge graph technologies, scientific informatics, and drug discovery and development, enabling us to deliver scalable, reliable, and impactful predictive platforms.
